At some point most software developers have to make a decision in their career. Do they move into a managerial role or do they continue as a software developer.
The Peter Principle is named after Laurence J. Peter who wrote a book in 1969 in which he suggests that people will always get promoted to level in which they are incompetent. The Principle states that you will get promoted based on your ability to do your current job and not on any assessment of how you would do your next role. Let's face it, this is especially true in the IT industry. How many strong developers have been promoted into a role out of their depth because they were technically strong?
Managing people is hard, much harder than it looks. If you want to avoid Peter Princpile you have to be aware of everything you do and say 100X more than you ever did before. You have to gain a deep understanding of what motivates people, you have to actively seek feedback and act upon it, you need to read and understand things like EQ, how teams form, how to create a diverse team, how to handle conflict, how to be a good mentor, how to set gaols how to lead people to the "right" solution through questions and dozens of other things. I warn you it is a much different job and you do not get the creative high you do from programming. However it can be rewarding in its own why.
Before making this kind of decision you really need to do some deep thinking about what makes you happy and where you want to be in the future.
Wednesday 28 May 2014
Saturday 15 June 2013
Gartner Magic Quadrant - Laziness in the Enterprise
Letsme be blunt, the Gartner Magic Quadrant is an awful way to choose software. It involves taking your brain almost completely out of the equation. Don't get me wrong, it is a brilliant business model for Gartner. You are selling information to large companies and getting other large companies to "lobby" their product. It is completely win/win for Gartner, for everyone else that listens to the crap they shovel it is far from a win.
Unfortunately, Garntner carries a lot of weight in the IT industry and the classic ass covering can be done by choosing something in the upper right quadrant. Most of the time when I look at the crap Gartner is shovelling I can't even find a tool I would want to use. The reason behind this? Well in order to even apply to get a product you need to spend hundreds and hundreds of hours producing a "landscape report" which most mid size companies would not concentrate on, especially when Garnter refuse to disclose how much inkickbacks fees they charge for "rating" your software.
So companies like Avaya are spending most of their time and effort on marketing but are building thee biggest pieces of shit I have ever seen. The software cannot meet half the business requirements despite the BS from their salespeople and integrating with them is like getting your teeth pulled by a proctologist. Yet somehow they make it into the upper right quadrant...
All Garntner has done is slow down and handicap anyone who takes their advice. Which is great for all the startups who are making smart decisions based on their business needs, not an arbitrary 4 quadrant graph which represents how much marketing budget they have....
Unfortunately, Garntner carries a lot of weight in the IT industry and the classic ass covering can be done by choosing something in the upper right quadrant. Most of the time when I look at the crap Gartner is shovelling I can't even find a tool I would want to use. The reason behind this? Well in order to even apply to get a product you need to spend hundreds and hundreds of hours producing a "landscape report" which most mid size companies would not concentrate on, especially when Garnter refuse to disclose how much in
So companies like Avaya are spending most of their time and effort on marketing but are building thee biggest pieces of shit I have ever seen. The software cannot meet half the business requirements despite the BS from their salespeople and integrating with them is like getting your teeth pulled by a proctologist. Yet somehow they make it into the upper right quadrant...
All Garntner has done is slow down and handicap anyone who takes their advice. Which is great for all the startups who are making smart decisions based on their business needs, not an arbitrary 4 quadrant graph which represents how much marketing budget they have....
Saturday 14 April 2012
CAP Theorem Explained
What is CAP Theorem?
The CAP Theorem(principle) was initially published in 1999 by a computer scientist by the name of Eric Brewer. It is basically making people aware of the trade offs when creating distributed systems. CAP stands for Consistency, Availability and Partition Tolerant - The principle states that you can have any 2 of the 3, but not all 3.
Available - The system will always return a result
Consistent- All data reads will return the latest write
Partition-Tolerant - The network is partitioned - EG you have 2 Data centers
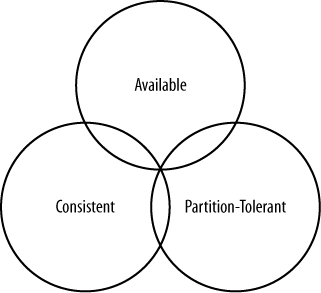
The CAP Theorem(principle) was initially published in 1999 by a computer scientist by the name of Eric Brewer. It is basically making people aware of the trade offs when creating distributed systems. CAP stands for Consistency, Availability and Partition Tolerant - The principle states that you can have any 2 of the 3, but not all 3.
Available - The system will always return a result
Consistent- All data reads will return the latest write
Partition-Tolerant - The network is partitioned - EG you have 2 Data centers
Lets Explore this a little more to understand why. If the above didn't make enough sense there is a video here.
Firstly with a distributed system you have multiple systems communicating with each other over a network, most of the time these systems all have isolated databases(nothing shared architecture) and use Asynchronous messaging to communicate. There are a few reasons people create these architectures, to scale, integrating existing systems, your CIO has a thing for buying random software or 100 other reasons.
Partition-Tolerant & Consistent
This is the choice if you need to have your data consistent. Now why can't you have availability as well? If you want to make things available you have to replicate it across multiple nodes. Now really this trade off could be considered latency, meaning if you were willing to wait, depending on volume(think ticketmaster) you can still make things available it just sucks. However, this is a valid scaling technique for a lot of use cases at Google(BigTable), Amazon etc. Examples would be Redis, Memcache, MongoBD(eventually consistent), and HBase. All of these have different implementations but share something in common, they do not allow reads until they can guarantee that it will be consistent.
Partition-Tolerant & Available
This is the choice most highly scaleable systems take, their data is almost consistent and most use methods like caching, messaging and eventual consistency, just to name a few, to make the user experience as smooth as possible. Examples would be RIAK, Cassandra and CouchDB, Most gossip protocols and eventually consistent systems are partition-tolerant and available. These systems will allow reads before ensuring all data is consistent.
Consistent & Available
This is where traditional Databases live and is not really considered an acceptable design in modern architectures. You can put a lot of hardware in front of them to scale up and for 99% of software, you will never need anything more. However, depending on how it is implemented it might not be easy to switch to a distributed architecture. Here is an interesting read on how ebay did it. Examples would be MSMSQL and MYSQL
Current CAP
The CAP principle was written 15 years ago, needless to say a lot of stuff has changed and it has served its purpose. An updated theory would say you need to choose between Consistency and Availability as Partitional Tolerance is a must. If you like to read more there is a great follow up called CAP - Twelve years later
The point of CAP is/was just to make people aware of the trade offs, which I believe has worked quite well. CAP has served its purpose and continues to be required reading for anyone who is attempting to build a distributed system.
Monday 15 February 2010
Reshaper and F# Remapping the Shortcuts
I installed F# the other day and when I went to fire up the interactive window I thought wait this seems really familiar... I am sure I use this command for something else, sure enough I was correct, it is a Resharper shortcut for quick edit.
Fortunately, as of version 1.9.9, they have made the shortcut super easy to find by calling it
Fortunately, as of version 1.9.9, they have made the shortcut super easy to find by calling it
EditorContextMenus.CodeWindow.SendToInteractiveIn version 1.9.4 it WAS called
Microsoft.Fsharp.Compiler.VSFSI.Connecdt.ML.SendSelectionbut I guess having the words FSharp in the name made it too easy to identify. If you too need to remap it go to Tools --> Options --> Environment --> Keyboard and type "SendTo" or "SendLine" to remap your F# interactive shortcut!
When to use a Window Services
Why does everything need to be a service? Almost every company I have worked for has requested some kind of automated process. Anything from a nightly ftp upload to cleaning up some DB records. Sure enough someone always suggests a windows service.
Windows says a service is:
Console App and the Windows Scheduler
Windows has a built in scheduler that is perfect for TIMED jobs, that in combination with the a simple console app is perfect for these types of requests. Simple to build, simple to debug, simple to deploy and simple to maintain. What asset does it bring to the business to create a Service? Most of the time the person doing the recommending either doesn't really know what a service is for or they are just attempting to challenge themselves? Console apps are so much better in most cases. You can kick off a console app whenever you want, you can change it and work with it on the fly, rerun it whenever you want, and generally speaking you are going have a harder time accidental bringing down a server with a console app
99% of the time a console app is going to be less intense on the server then a service especially if that service is poorly written, like the person that suggests we build a service with a timer to kick off processes, probably should not be your first choice of someone to take advice from.
Windows Services
Windows Services can be very useful and necessary but like everything it needs to be used when the business needs actually justify it. If you need to monitor a directory, use a service. If something on the server needs to up and running at all times, use a service. Services do have some built in advantages over a console app such as failure recovery. Such as "do nothing", "restart the service", "run a different app" or "restart the computer". I personally love the restart the computer option.
Both Windows Services and console/windows scheduler have their place just be sure you have a think about what you really need and how much business value the service your itching to build really brings.
Windows says a service is:
A program, routine, or process that performs a specific system function to support other programs, particularly at a low (close to the hardware) level. When services are provided over a network, they can be published in Active Directory, facilitating service-centric administration and usage. Some examples of services are the Security Accounts Manager service, File Replication service, and Routing and Remote Access service.
Console App and the Windows Scheduler
Windows has a built in scheduler that is perfect for TIMED jobs, that in combination with the a simple console app is perfect for these types of requests. Simple to build, simple to debug, simple to deploy and simple to maintain. What asset does it bring to the business to create a Service? Most of the time the person doing the recommending either doesn't really know what a service is for or they are just attempting to challenge themselves? Console apps are so much better in most cases. You can kick off a console app whenever you want, you can change it and work with it on the fly, rerun it whenever you want, and generally speaking you are going have a harder time accidental bringing down a server with a console app
99% of the time a console app is going to be less intense on the server then a service especially if that service is poorly written, like the person that suggests we build a service with a timer to kick off processes, probably should not be your first choice of someone to take advice from.
Windows Services
Windows Services can be very useful and necessary but like everything it needs to be used when the business needs actually justify it. If you need to monitor a directory, use a service. If something on the server needs to up and running at all times, use a service. Services do have some built in advantages over a console app such as failure recovery. Such as "do nothing", "restart the service", "run a different app" or "restart the computer". I personally love the restart the computer option.
Both Windows Services and console/windows scheduler have their place just be sure you have a think about what you really need and how much business value the service your itching to build really brings.
Sunday 15 February 2009
Caching in .NET
As applications grow it is quite normal to leverage caching as a way to gain scalability and keep consistent server response times. Caching works by storing data in memory to drastically decrease access times. To get started I would look at ASP.NET caching.
There are 3 types of general Caching techniques in ASP.NET web apps:
Page Output Caching(Page Level)
Page Partial-Page Output(Specific Elements of the page)
Programmatic or Data Caching
Output Caching
Page level output caching caches the html of a page so that each time ASP.NET page requested it checks the output cache first. You can vary these requests by input parameters(VaryByParam) so the the page will only be cached for users where ID=1 if a requests come in where ID=2 asp.net cache is smart enough to know it needs to re-render the page.
Partial-Page Caching
a lot of times it wont make sense to cache the entire page in these circumstances you can use partial Page caching. This is usually used with user controls and is set the same way as page level only adding the OutputCache declarative inside the usercontrol.
Data Caching
You can store objects or values that are commonly used throughout the application. It can be as easy to as:
Cache["myobject"] = person;
Enterprise Level Caching
It is worth mention that there are many Enterprise level caching architectures that have come about to leverage the effectiveness caching. Memcache for .net and Velocity are a couple.
In General
You can't really make blanket statements on what you should and shouldn't cache because every application is different. However, you can make a few generalizations that hold true MOST of time. Static elements like images and content are OK to cache. Even a dynamic page that is getting hammered is worth caching for 5-10 seconds, it will make a world of difference to your web server.
Caching overview
There are 3 types of general Caching techniques in ASP.NET web apps:
Page Output Caching(Page Level)
Page Partial-Page Output(Specific Elements of the page)
Programmatic or Data Caching
Output Caching
Page level output caching caches the html of a page so that each time ASP.NET page requested it checks the output cache first. You can vary these requests by input parameters(VaryByParam) so the the page will only be cached for users where ID=1 if a requests come in where ID=2 asp.net cache is smart enough to know it needs to re-render the page.
Partial-Page Caching
a lot of times it wont make sense to cache the entire page in these circumstances you can use partial Page caching. This is usually used with user controls and is set the same way as page level only adding the OutputCache declarative inside the usercontrol.
Data Caching
You can store objects or values that are commonly used throughout the application. It can be as easy to as:
Cache["myobject"] = person;
Enterprise Level Caching
It is worth mention that there are many Enterprise level caching architectures that have come about to leverage the effectiveness caching. Memcache for .net and Velocity are a couple.
In General
You can't really make blanket statements on what you should and shouldn't cache because every application is different. However, you can make a few generalizations that hold true MOST of time. Static elements like images and content are OK to cache. Even a dynamic page that is getting hammered is worth caching for 5-10 seconds, it will make a world of difference to your web server.
Caching overview
Inline Functions in C#
What are They?
In the terms of C and C++ you use the inline keyword to tell the compiler to call a routine without the overhead of pushing parameters onto the stack. The Function instead has it's machine code inserted into the function where it was called. This can create a significant increase in performance in certain scenarios.
Dangers
The speed benefits in using "inlineing" decrease significantly as the size of the inline function increases. Overuse can actaully cause a program to run slower. Inlining a very small accessor function will usually decrease code size while inlining a very large function can dramatically increase code size.
Inlining in C#
In C# inlining happens at the JIT level in which the JIT compiler makes the decision. There is currently no mechanism in C# which you can explicitly do this. If you wish to know what the JIT compiler is doing then you can call System.Reflection.MethodBase.GetCurrentMethod().Name at runtime. If the Method is inlined it will return the name of the caller instead.
In C# you cannot force a method to inline but you can force a method not to. If you really need access to a specific callstack and you need to remove inlining you can use : MethodImplAttribute with MethodImplOptions.NoInlining. In addition if a method is declared as virtual then it will also not be inlined by the JIT. The reason behind this is that the final target of the call is unknown.
More on inline here
In the terms of C and C++ you use the inline keyword to tell the compiler to call a routine without the overhead of pushing parameters onto the stack. The Function instead has it's machine code inserted into the function where it was called. This can create a significant increase in performance in certain scenarios.
Dangers
The speed benefits in using "inlineing" decrease significantly as the size of the inline function increases. Overuse can actaully cause a program to run slower. Inlining a very small accessor function will usually decrease code size while inlining a very large function can dramatically increase code size.
Inlining in C#
In C# inlining happens at the JIT level in which the JIT compiler makes the decision. There is currently no mechanism in C# which you can explicitly do this. If you wish to know what the JIT compiler is doing then you can call System.Reflection.MethodBase.GetCurrentMethod().Name at runtime. If the Method is inlined it will return the name of the caller instead.
In C# you cannot force a method to inline but you can force a method not to. If you really need access to a specific callstack and you need to remove inlining you can use : MethodImplAttribute with MethodImplOptions.NoInlining. In addition if a method is declared as virtual then it will also not be inlined by the JIT. The reason behind this is that the final target of the call is unknown.
More on inline here
Subscribe to:
Posts (Atom)